The Artificial Characters Learning Problem
This database has been artificially generated by using a first order
theory which describes the structure of ten capitol letters of the
English alphabet and a random choice theorem prover which accounts
for etherogeneity in the instances. The capitol letters represented
are the following: A, C, D, E, F, G, H, L, P, R.
Each instance is structured and is described by a set of segments (lines)
which resemble the way an automatic program would segment an image.
The following picture shows some of the instances.
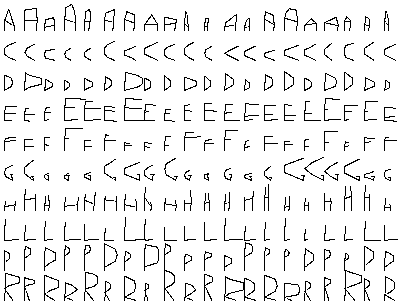
In turn, each segment in an instance is described by seven attributes, four of
which are the really necessary, one is superflous, and the other two can be
computed from the necessary ones, but are present for efficiency reasons.
Instances are stored in tabular form: rows describe the segments, and
columns corresponds to attribute values, according to the following format:
- #id of the instance
- #class is an integer number indicating the class as described below
- #objnum is an integer identifier of a segment (starting from 0) in the
instance
- type of segment: specifies the type of a segment and is always
set to the string "line". Its C language type is char.
- xx1,yy1,xx2,yy2: these attributes contain the initial and final coordinates
of a segment in a cartesian plane. Their C language type is int.
- size: this is the length of a segment computed by using the geometric
distance between two points A(xx1,yy1) and B(xx2,yy2). Its C language type is float.
- diag: this is the length of the diagonal of the smallest rectangle
which includes the picture of the character. The value of this
attribute is the same in each object. Its C language type is float.
There are no missing attribute values.
Up to now, there are seven data files available: six files containing 1000
instances each (100 per class), and an independent test set containing
10000 instances (1000 per class). To download these datasets just click on
the following items:
Note: in each file instances are numbered from 1 to 1000, so you may need to
renumber them when putting together two or more folds.
The class value (CLASS) can take ten different values. Each letter belongs
to only one of the classes. Instances are evenly distributed over the classes,
as shown in the following table:
CLASS NAME FOLD 0 FOLD 1 ... FOLD 6 TESTSET TOTAL
1 A 100 100 100 1000 1600
2 C 100 100 100 1000 1600
3 D 100 100 100 1000 1600
4 E 100 100 100 1000 1600
5 F 100 100 100 1000 1600
6 G 100 100 100 1000 1600
7 H 100 100 100 1000 1600
8 L 100 100 100 1000 1600
9 P 100 100 100 1000 1600
10 R 100 100 100 1000 1600
-----------------------------------------------------------
TOTAL 1000 1000 1000 10000 16000
We performed many experiments on these datasets by using Smart+ and more
recently by combining Smart+ and two numerical knowledge refinement systems
we develop. In the experiments performed by Smart+ and reported in the paper
by M. Botta, and A. Giordana:
"SMART+: A MultiStrategy Learning Tool", Proc. of the IJCAI-93 (Chambery, France, 1993), pp. 937-943,
we used the first fold as learning set and the remaining
five folds as test set (at that time the independent test set were not available).
The results obtained on this data sets are the following:
Type of Optimization Recognition Rate Error Rate Ambiguity Rate
No OPT 41.48% 3.82% 54.70%
Local OPT 98.68% 0.12% 1.20%
Local+GA OPT 99.70% 0.0% 0.30%
In a recent paper, M. Botta, A. Giordana, and R. Piola:
"An integrated framework for learning numerical terms in FOL", Proc.
of the ECAI-98, (Brighton, UK, 1998), pp. 415-419, we report preliminary
results on using Smart+ to acquire an initial knowledge base that is then
refined by FONN and NTR, two refinement systems based on the error gradient
descent technique.
|
