The Spoken Digits Learning Problem
The problem concerns the recognition of the ten digits spoken in Italian
as isolated words, starting from the time evolution of two rough features,
namely the zero-crossing and the total energy of the signal.
The following picture shows a typical graph of the total energy of a "zero"
spoken digit.
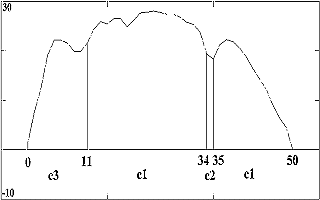
The features are extracted from the signal using classical signal processing
algorithms and then described by using a set of primitives as proposed in
R. DeMori, A. Giordana, P. Laface and L.Saitta: "An expert system for mapping
acoustic cues into phonetic features", Information Sciences,
vol. 33, pp 115-155.
In particular, the graphs of the two features are
segmented into contiguous intervals corresponding to four types of
elementary shapes, further characterized by four numeric attributes.
Each instance is made of two groups of elementary objects, one describing
properties of total energy segments (objects labelled "et") and one
describing properties of zero-crossing segments (objects labelled "zc").
Data are stored in tabular form, similarly to a textual representation of
a relation of a relational database, each line describing a segment of an
instance. The data file has 10 columns, whose meaning is the following:
- 1) #id of the instance
- 2) #class (1="zero", 2="uno", 3="due", 4="tre", 5="quattro",
6="cinque", 7="sei", 8="sette", 9="otto", 10="nove")
- 3) #id of the part of the instance (0-based)
- 4) type of object: specifies if the object belongs to the zero crossing "zc" or to the
total energy "et".
- 5) shape of object: c1 (a peak), c2 (flat segment), c3 (monotonically increasing segment), c4 (monotonically decreasing segment)
- 6) initial time in centiseconds.
- 7) end time in centiseconds.
- 8) width in centiseconds (this is redundant)
- 9) max height in dB
- 10) area of the segment (integral of the function over the interval)
Columns 1 (instance id) and 3 (object id) constitute a key to uniquely
identify a particular segment in the dataset.
Relevant a-priori knowledge:
- all instances start and terminate with a 'c2' shape
object of null area (this is due to the segmentation algorithm); since this
might be misleading for some system, it is suggested to discard these objects
(in all our systems, we used a predicate 'central(x)', that is true if an
objects neither starts nor ends a signal).
- useful features that can be extracted from the data and used for
learning includes:
- comparing width, height and area of two segments with same shape
- comparing width, height and area of two segments from same signal (et or zc)
- comparing width, height and area of two segments from different signals
- mutual position of two segments from same signal
- mutual position of two segments from different signals
The file training.data.gz contains 219 instances
(22 per class, 21 for the last class) used as learning set, whereas the
file test.data.gz contains 100 instances (10 per class)
used as test set.
The best results obtained on this problem by our systems are the following:
First version of ML-Smart (*)
Correct classifications : 77 77.00 %
Wrong classifications : 0 0.00 %
Ambiguously-classified (with correct class) : 23 23.00 %
Ambiguities among two classes : 9 9.00 %
Ambiguities among four classes : 7 7.00 %
Ambiguities among six classes : 7 7.00 %
Ambiguously-classified (without correct class) : 0 0.00 %
Smart+ (not published)
Correct classifications : 75 75.00 %
Wrong classifications : 9 9.00 %
Ambiguously-classified (with correct class) : 16 16.00 %
Ambiguities among two classes : 14 14.00 %
Ambiguities among three classes : 1 1.00 %
Ambiguities among four classes : 1 1.00 %
Ambiguously-classified (without correct class) : 0 0.00 %
Smart+ + NTR (**)
Correct classifications : 82 82.00 %
Wrong classifications : 9 9.00 %
Not classified : 9 9.00 %
Smart+ + FONN (**)
Correct classifications : 82 82.00 %
Wrong classifications : 6 6.00 %
Not classified : 12 12.00 %
(*) Results published in F. Bergadano, A. Giordana and L. Saitta:
"Automated Concept Acquisition in Noisy Environments",
IEEE Trans. on Pattern Analysis and Machine Intelligence, PAMI-10, 1988,
pp 555-578.
(**) Preliminary results published in M. Botta, A. Giordana, and R. Piola:
"An integrated framework for learning numerical terms in FOL", Proc.
of the ECAI-98, (Brighton, UK, 1998), pp. 415-419.
|
