


Our framework is concerned with information-seeking dialogues in the domain of a CS Department [Ardissono et al. 1993b].
The general knowledge about actions and plans is stored in a plan library
structured on the basis of two main hierarchies: the Decomposition Hierarchy
(DH) and the Generalization Hierarchy (GH) [Kautz and Allen1986]. The DH
is used for explaining how to execute complex actions. In particular, actions
may be elementary or complex and, in the second case, one or more plans may be
associated with them. The GH makes explicit the
relation between more specific and more general actions and is
used for exploiting inheritance in their definition. Each action is
characterized by its preconditions, constraints, restrictions on the parameters,
postconditions and decomposition. Figure
The GH makes explicit the
relation between more specific and more general actions and is
used for exploiting inheritance in their definition. Each action is
characterized by its preconditions, constraints, restrictions on the parameters,
postconditions and decomposition. Figure  represents a
portion of the plan library, concerning the PREP-AND-TAKE-CS-EX action. In the
figure, dashed arcs are specialization links between actions, while solid arcs
are used for identifying the preconditions, postconditions, constraints and
decompositions of actions. For the sake of simplicity, the definition of the
elementary actions has been omitted.
represents a
portion of the plan library, concerning the PREP-AND-TAKE-CS-EX action. In the
figure, dashed arcs are specialization links between actions, while solid arcs
are used for identifying the preconditions, postconditions, constraints and
decompositions of actions. For the sake of simplicity, the definition of the
elementary actions has been omitted.
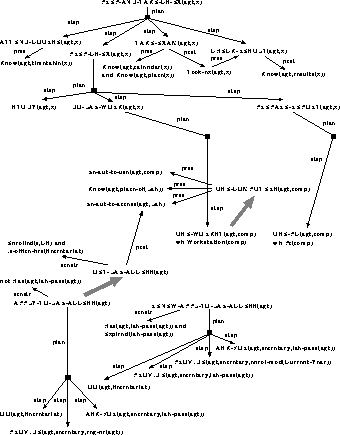
Figure: A portion of the Plan Library
In the GH, more specific actions may be related to more general ones by a subsumption relation among the types of their parameters. In the figure, USE-PC and USE-WORKST are more specific than USE-COMPUTERS, because they have an additional restriction on their second parameter: while ``comp'' is restricted to be a computer in USE-COMPUTERS, in the subsumed actions it is respectively a PC or a workstation. Moreover, actions may be more specific than others because they represent specific modalities of execution (corresponding to alternative decompositions). For example, talking to people by phone or face to face are two alternative ways of communicating.
We assume that the system has complete knowledge about the actions that may be
performed in the domain and that the users' world models are consistent with the
system's (in general, they may be subsets). In particular, users are not
aware of any actions (or ways of executing actions) other than those represented
in the plan library (the appropriate query assumption,
[Pollack1990]). So, the system is always able to find some plans associated
with their utterances. However, the system may not be informed
about the truth value of very specific facts (e.g. it may not know whether a
certain book is present in the library): in such cases, it is able to
suggest a plan for retrieving the information.
The interpretation framework is composed of four main modules:
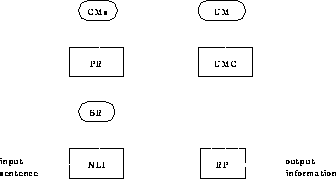
Figure: The general architecture
Figure , which represents a schema of the architecture, shows
the information flow across the various modules. The semantic representation
of the input sentence (SR) is used by the PR module as the basis for the
identification of the users' plans (represented as CMs) and it is also fed to the UMC component, that uses
it to acquire information about users on the basis of what they say.
The interaction between PR and UMC is the core of this paper: the information
in the UM is used (by means of PR requests to UMC) for identifying as
precisely as possible the users' plans. Vice versa, UMC analyses the contents
of the active CMs (by means of requests to PR) to reason over them in order
to make safe inferences in the UM. Finally, RP expands the active
CMs with the information
necessary to reply to the users' utterances with answers suitable to their
competence in the domain. The UM is then updated to take into account the new
supplied knowledge.
In the following we will introduce the PR and UMC modules: on the other hand,
we will not discuss the NLI and RP components, which are outside the scope of
the paper. The plan recognition module is based on the framework proposed in
[Carberry1988], where CMs represent the system's hypotheses on the user's
plans collected during the dialogue. In her system, the ambiguity among the
hypothesized plans is solved by means of an evaluation of their plausibility
mainly based on the intentions explicitly stated during the dialogue.
However, as we already pointed out, knowledge about users is
very important in the disambiguation of their intentions; so, we use the
information collected in the UM to select the set of most promising hypotheses
built during a dialogue. If, at a certain point, some unsolvable ambiguities
arise that cannot be ignored because they affect the system's reactions to
the user's utterances, we start a clarification dialogue to investigate
the user's real plans.
We believe that an important aspect in the generation of the answer is
the trade-off between the need to identify with precision the users' plans
and goals and the requirement of keeping clarification dialogues short
to increase the acceptability of the system. This is why the use of the
information collected by means of user modeling techniques may have a strong
impact on the naturalness of dialogues.
In order to take into account
the fact that the system can also provide an answer in cases where its
knowledge of the domain is limited, we (see
[Ardissono et al.
1993a]) have adopted and refined the
notion of relevance of ambiguities introduced in [van Beek et al.
1993].
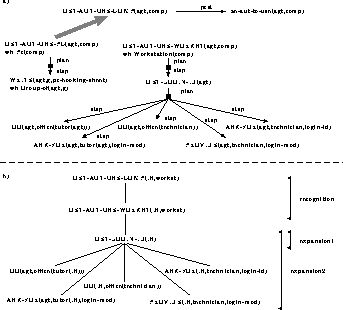
Figure: A piece of the Plan Library and an example of Context Model
In the construction of the UM, the system uses stereotypical information and
acquisition rules that infer users' beliefs and knowledge directly from their
utterances. The UM is then expanded by means of inferences on
the beliefs already contained in it.
The presence of a rich UM is very important in the resolution of the ambiguities
among the active hypotheses on a user's plans. Moreover, it enhances the
flexibility and the acceptability of the system, because it makes it possible to
build answers at different levels of detail, according to the user's
acquaintance with the domain concepts and actions. For this reason, we have
extended Carberry's
basic plan recognition algorithm so that, during the dialogue, CMs
are completed with information that adapts them to the detail level required
by the user's domain knowledge. In other words, CMs have a double role in
the representation of discourse: while their upper part represents the active
hypotheses on the users' intentions, the lower one, added during the
completion phase, specifies which information must be provided for
answering in a helpful way. Less detailed CMs are
built for expert users, while the actions hypothesized for novices include
more information (e.g. the steps in the plan for
executing a complex action are added to a CM or omitted, according to the
assumption that users know how to perform the action, or they need an
explanation of it). For example, referring to Figure .a, if
an agent says: ``I want to get the authorization to use the workstations. What
should I do?'', the system identifies the GET-AUT-USE-WORKST action.
According to the user's degree of acquaintance with the domain, two different
answers may be given: the shortest one is to explain that s/he should get
a login id. However, if (on the basis of the previous part of the dialogue) the
UM suggests that the user knows very little about the CS Department, the
procedure for getting the login id could be explained, too. The two
situations correspond to different expansions of the CM representing the
user's plans. Figure .b shows the CM built in the second situation
and the brackets in it divide the part of the CM representing the
recognized plans from that added for answering in the appropriate way.